Interpretable Probabilistic Graphical Models¶
The Mid-Level API lets you describe any interpretable deep learning model as a probabilistic graphical model (PGM): a set of random variables connected by factors. Different probabilistic inferences can be performed on the PGM. It is the right entry point if you think in terms of probabilistic or causal models.
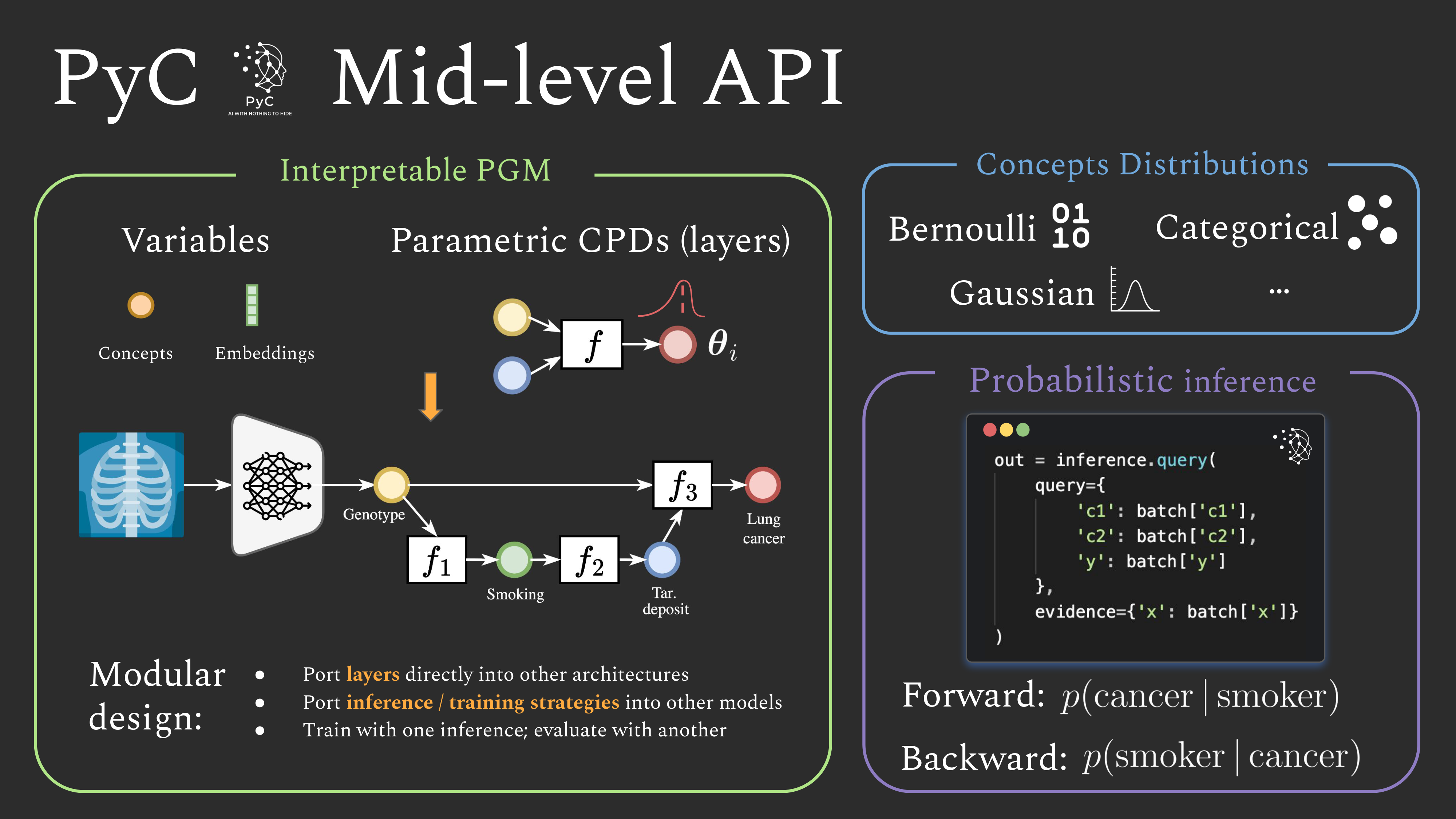
A mid-level model is assembled from four building blocks:
Variables — the random variables (concepts, embeddings) that make up the model.
Factors — conditional distributions or potential functions wiring variable together.
ProbabilisticModel — the container that collects variables and factors into a PGM.
Inference — engines that answer queries over the model.
Expand each block below for an explanation and an example. The running example builds a
Concept Bottleneck Model input → latent → concepts → task as a probabilistic model.
Variables
A Variable is a random variable in the model. Two concrete kinds are
provided:
ConceptVariable— an interpretable, named variable (a concept or a task). A single call can declare several concepts at once.EmbeddingVariable— a vector-valued node (e.g. the raw input or a latent representation), typically given aDeltadistribution.
A variable is defined by its name, its distribution (torch.distributions), and
its size (scalar) or shape (multi-dimensional, e.g. an image tensor).
import torch_concepts as pyc
from torch.distributions import Bernoulli, OneHotCategorical, Normal
from torch_concepts import EmbeddingVariable, ConceptVariable
from torch_concepts.distributions import Delta
input_var = EmbeddingVariable("input", distribution=Delta, shape=(3, 224, 224)) # RGB image
latent_var = EmbeddingVariable("latent", distribution=Delta, size=64)
smoking = ConceptVariable("smoking", distribution=Bernoulli)
genotype = ConceptVariable("genotype", distribution=OneHotCategorical, size=3)
tar = ConceptVariable("tar", distribution=Normal)
cancer = ConceptVariable("cancer", distribution=Bernoulli)
Passing a list of names creates independent variables (one node per concept in the
graph). To group several concepts under a single node — one factor covers all of them
— use a plate variable with members:
# One graph node; members are addressed individually for fine-grained parent wiring
binary_concepts = ConceptVariable("binary_concepts", distribution=Bernoulli,
members=["smoking", "cancer"])
smoking_handle = binary_concepts.member("smoking") # parent handle for downstream factors
Factors
A factor encodes a relationship over a set of variables and it is the building block that
gives a PGM its structure. The abstract base class is
ParametricFactor; different subclasses encode different kinds of
relationship (conditional distributions for directed graphs, potential functions for
undirected ones, etc.).
Currently, the only implemented factor is ParametricCPD — a
conditional probability distribution p(variable | parents) parameterised by a
 PyC or
PyC or  PyTorch module. Support for undirected factors (potentials)
is planned for the near future.
PyTorch module. Support for undirected factors (potentials)
is planned for the near future.
Each ParametricCPD declares its parents, which is exactly how the directed graph
structure is defined. The parametrization dict keys must match the distribution’s
constructor arguments (e.g., logits for a Bernoulli distribution). Parent-less (root) variables use a prior such as
LearnablePrior.
from torch_concepts.nn import ParametricCPD, LearnablePrior, Sequential, LinearConceptToConcept, LinearEmbeddingToConcept
import torch.nn as nn
# Input —> root, generally provided as evidence at inference time
input_cpd = ParametricCPD(
input_var,
parents=[],
parametrization=LearnablePrior(size=1)
)
# Latent | Input —> Delta (deterministic backbone)
latent_cpd = ParametricCPD(
latent_var,
parents=[input_var],
parametrization=nn.Sequential(nn.Flatten(), nn.Linear(3 * 224 * 224, 64), nn.ReLU())
)
# Genotype | Latent —> OneHotCategorical, parametrize logits
genotype_cpd = ParametricCPD(
genotype,
parents=[latent_var],
parametrization={'logits': LinearEmbeddingToConcept(in_embeddings=64, out_concepts=3)},
)
# Smoking | Genotype —> Bernoulli, parametrize logits
smoking_cpd = ParametricCPD(
smoking,
parents=[genotype],
parametrization={'logits': LinearConceptToConcept(in_concepts=3, out_concepts=1)},
)
# Tar | Smoking —> Normal, both loc and scale must be parametrized; scale must be positive
tar_cpd = ParametricCPD(
tar,
parents=[smoking],
parametrization={
'loc': LinearConceptToConcept(in_concepts=1, out_concepts=1),
'scale': Sequential(LinearConceptToConcept(in_concepts=1, out_concepts=1), nn.Softplus()),
},
)
# Cancer | Genotype, Tar —> Bernoulli, parametrize logits
cancer_cpd = ParametricCPD(
cancer,
parents=[genotype, tar],
parametrization={'logits': LinearConceptToConcept(in_concepts=4, out_concepts=1)},
)
ProbabilisticModel
ProbabilisticModel is the abstract base for probabilistic graphical
models. The concrete class you instantiate is BayesianNetwork, a
directed model that wires a list of variables to a list of factors (one factor per variable).
from torch_concepts.nn import BayesianNetwork
model = BayesianNetwork(
variables=[input_var, latent_var, genotype, smoking, tar, cancer],
factors=[input_cpd, latent_cpd, genotype_cpd, smoking_cpd, tar_cpd, cancer_cpd],
)
Inference
An inference engine answers queries of the form “give me these variables, given this
evidence” via engine.query(query, evidence). PyC ships several engines:
DeterministicInference— propagates distribution parameters in topological order (a standard deep-learning forward pass). Use this for training and point predictions.AncestralSamplingInference— draws a (reparameterised) sample per variable in topological order.ForwardInference,IndependentInference,RejectionSampling,ImportanceSampling, and the Pyro-backedVariationalInferenceprovide further probabilistic alternatives.
query accepts a list of variable names (predict them) or a dict mapping names to
observed values (clamp them as evidence, e.g. for teacher forcing during training). The result
exposes per-variable distribution parameters in out.params[name] and samples (when applicable)
in out.samples[name].
from torch_concepts.nn import DeterministicInference
inference = DeterministicInference(model, activate_before_propagation=True)
x = torch.randn(16, 3, 224, 224)
out = inference.query(query=["genotype", "smoking", "tar", "cancer"], evidence={'input': x})
genotype_logits = out.params['genotype']['logits'] # (16, 3)
cancer_logits = out.params['cancer']['logits'] # (16, 1)
Putting it Together: Concept Bottleneck Model
The blocks above assemble into a full CBM. During training, pass observed concept and task values as the query dict — they are clamped as evidence for teacher forcing:
import torch
from torch.distributions import Bernoulli
from torch_concepts import EmbeddingVariable, ConceptVariable
from torch_concepts.distributions import Delta
from torch_concepts.nn import (
LinearEmbeddingToConcept, LinearConceptToConcept,
ParametricCPD, BayesianNetwork, DeterministicInference, LearnablePrior,
)
x_var = EmbeddingVariable("x", distribution=Delta, size=16)
c_var = ConceptVariable(["c1", "c2"], distribution=Bernoulli)
y_var = ConceptVariable("y", distribution=Bernoulli)
model = BayesianNetwork(
variables=[x_var, *c_var, y_var],
factors=[
ParametricCPD(x_var, parents=[], parametrization=LearnablePrior(size=1)),
ParametricCPD(c_var, parents=[x_var],
parametrization={'logits': LinearEmbeddingToConcept(16, out_concepts=1)}),
ParametricCPD(y_var, parents=[*c_var],
parametrization={'logits': LinearConceptToConcept(2, out_concepts=1)}),
],
)
inference = DeterministicInference(model, activate_before_propagation=True)
# At training time, pass observed labels as query to clamp them as evidence
x = torch.randn(32, 16)
c_true = torch.randint(0, 2, (32, 2)).float()
y_true = torch.randint(0, 2, (32, 1)).float()
pred = inference.query(query={"c1": c_true[:, 0], "c2": c_true[:, 1], "y": y_true},
evidence={"x": x})
Next Steps¶
Browse the full Mid-Level API reference.
Drop down to the Semantic primitives and Interventions to customise the layers behind each factor.
Move up to the Out-of-the-box Models for the same models, pre-assembled.
Check out the mid-level example scripts.